Comparaison des performances de Llama 3 et de ses concurrents en 2025


Llama 3 joue un rôle crucial dans le domaine des modèles de langage. En 2025, Meta dévoile Llama 3 2 et déclare que c'est "le LLM le plus performant à ce jour". Ce modèle existe en trois tailles : 8B, 70B et 400B. Les scores de référence de Llama 3 rivalisent avec ceux de ChatGPT et le surpassent dans plusieurs domaines.
Les principaux concurrents de Llama 3 incluent GPT-4 et Claude, qui se distinguent par leurs propres caractéristiques. Comparer les performances de ces modèles vous aide à choisir celui qui répond le mieux à vos besoins spécifiques.
Points Clés
Llama 3 est spécial car il crée des textes de bonne qualité. Il comprend aussi des situations compliquées.
Les modèles de langage, comme Llama 3, s'améliorent toujours. Ils offrent de bonnes solutions pour différents projets.
Il est important de choisir le bon modèle pour vos besoins. Cela aide à obtenir de meilleurs résultats et à économiser de l'argent.
Les modèles gratuits, comme Llama 3, aident les petites entreprises et les développeurs à utiliser la technologie.
Les nouvelles améliorations dans les modèles de langage rendent les tâches plus efficaces et précises, comme créer du contenu.
Critères de comparaison
Lorsque vous évaluez les performances des modèles de langage, plusieurs critères de comparaison s'avèrent essentiels. Ces critères vous aident à déterminer quel modèle répond le mieux à vos besoins.
Performance générale
La performance générale d'un modèle de langage se mesure à l'aide de plusieurs indicateurs. Voici quelques-uns des plus importants :
F1-score : Harmonise les métriques pour une mesure globale de performance.
BLEU Score : Compare la similarité entre le texte généré et le texte de référence.
Human evaluation : Joue un rôle crucial pour ajuster les modèles au-delà des chiffres.
Ces mesures vous permettent de mieux comprendre comment Llama 3 se positionne par rapport à ses concurrents comme GPT-4 et Claude.
Capacité de génération de texte
La capacité de génération de texte est un aspect fondamental. En 2025, des modèles comme Gemini Ultra et Claude 2 affichent des performances impressionnantes. Par exemple, Gemini Ultra atteint 90,0 % sur le MMLU, surpassant même des experts humains. En revanche, Llama 3, avec sa version "meta devoile llama 3 2", continue de rivaliser avec ces modèles grâce à sa capacité à produire des textes cohérents et pertinents.
Raisonnement et compréhension
Le raisonnement et la compréhension sont également cruciaux. Les modèles de langage montrent des capacités de raisonnement inductif, mais ils manquent souvent de raisonnement déductif. Une étude de l'université de Californie à Los Angeles a révélé que les modèles réussissent bien dans des tâches de raisonnement inductif, mais peinent dans des scénarios plus complexes. Cela souligne l'importance de choisir un modèle qui excelle dans les domaines qui vous intéressent.
En résumé, ces critères de comparaison vous aident à évaluer les performances de Llama 3 et de ses concurrents. En tenant compte de ces éléments, vous pouvez faire un choix éclairé pour vos projets.
Applications pratiques
Les applications pratiques des modèles de langage en 2025 montrent leur impact significatif dans divers domaines. Vous pouvez observer comment ces modèles améliorent l'efficacité et la précision dans des tâches spécifiques. Voici quelques exemples d'applications :
Génération de contenu : Les modèles comme Gemini génèrent des textes publicitaires adaptés au contenu des sites web. Cela permet aux entreprises d'atteindre leur public cible de manière plus efficace.
Compréhension du langage naturel : LlaMA se révèle polyvalent pour diverses tâches, y compris la compréhension du langage naturel. Cela facilite l'interaction entre les utilisateurs et les systèmes automatisés.
Les innovations récentes dans les modèles de langage ont également conduit à des améliorations notables. Voici un tableau qui résume certaines de ces innovations et leur impact :
Innovation | Impact sur la performance | Coût par requête |
|---|---|---|
RAG | Amélioration de la précision | Réduction significative des coûts |
LLM2Vec | Performance accrue pour les applications spécialisées | Optimisation des ressources |
Many-Shot ICL | Précision améliorée | Diminution des besoins en données |
Ces avancées montrent comment les modèles de langage s'adaptent aux besoins des utilisateurs. Vous pouvez tirer parti de ces technologies pour améliorer vos projets. Que ce soit pour la création de contenu, l'analyse de données ou l'automatisation des tâches, les modèles comme Llama 3 et ses concurrents offrent des solutions puissantes. En choisissant le bon modèle, vous optimisez vos résultats et réduisez les coûts associés à vos projets.
Performances spécifiques de Llama 3

Génération de texte
Llama 3 se distingue par sa capacité à produire des textes riches en contexte. Ce modèle répond efficacement aux instructions, ce qui témoigne d'une forte compréhension des nuances. En comparaison, ChatGPT 4 génère des réponses engageantes, mais Llama 3 excelle dans la qualité du texte. Voici un tableau qui résume les performances de Llama 3 par rapport à ChatGPT 4 :
Critères | Llama 3 | ChatGPT 4 |
|---|---|---|
Qualité du texte généré | Excellente compréhension des détails | Réponses plus engageantes |
Créativité dans les formats | Moins de variabilité de style | Avantage dans la créativité |
Exactitude factuelle | Parfois inférieure | Souvent supérieure |
Cohérence logique | Supérieure | Variable |
Efficacité de la génération de code | Très compétent | Excellente syntaxe |
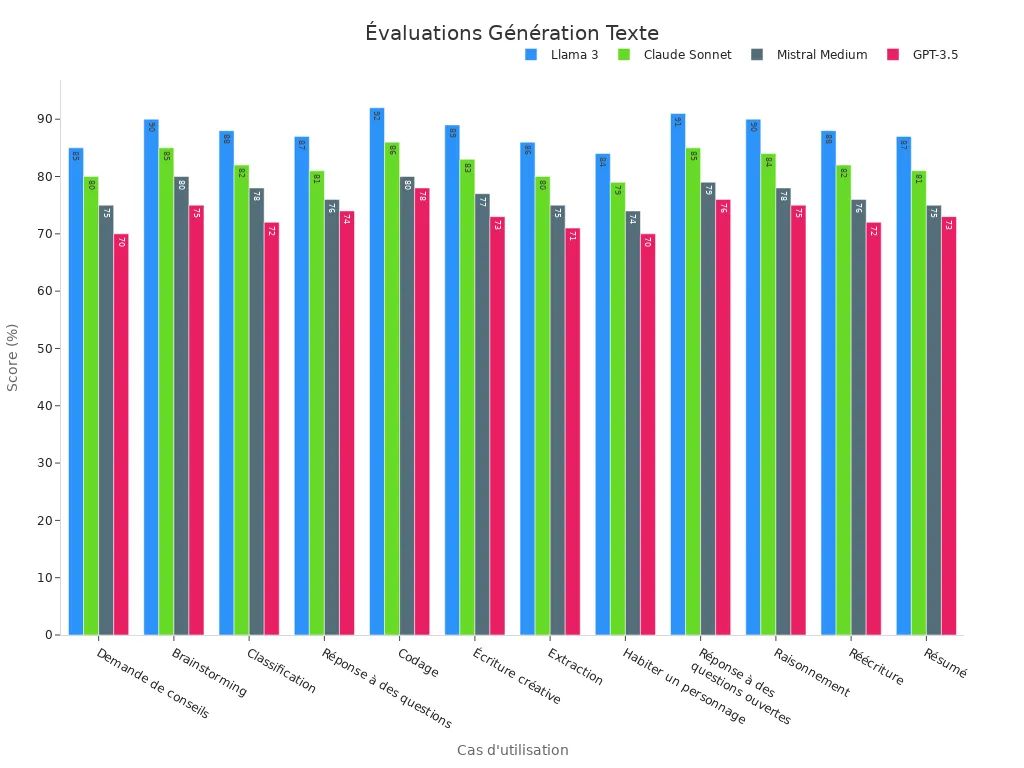
Les scores de Llama 3 dans des cas d'utilisation variés montrent son efficacité. Par exemple, il obtient 85 % pour les demandes de conseils et 90 % pour le brainstorming. Ces résultats illustrent comment Llama 3 surpasse ses concurrents dans plusieurs domaines.
Raisonnement
Le raisonnement est un autre domaine où Llama 3 brille. Ce modèle utilise plus de 400 TFLOPS par GPU lors de l'entraînement sur 16 000 GPU. Cette puissance de calcul permet à Llama 3 d'analyser des données complexes et de fournir des réponses précises. Un benchmark a été créé avec 1 800 prompts couvrant douze cas d'usage clés. Llama 3 surpasse d'autres modèles comme Claude 3 Sonnet et GPT-3.5 dans ces évaluations.
Les capacités de raisonnement de Llama 3 sont mises en avant par des évaluations humaines. Les utilisateurs constatent que ce modèle excelle dans des tâches de raisonnement inductif et déductif. En 2025, avec la version "meta devoile llama 3 2", Llama 3 continue d'améliorer ses performances, offrant ainsi des solutions adaptées aux besoins des utilisateurs.
Analyse des concurrents
GPT-4
GPT-4 reste un modèle de référence en 2025. Il affiche des performances solides dans divers benchmarks. Par exemple, il obtient un score de 86,4 % sur le MMLU et 67,0 % sur HumanEval. Ces résultats montrent que GPT-4 continue d'être un choix populaire pour les développeurs. Vous pouvez consulter des articles qui passent en revue les benchmarks et comparent les performances de GPT-4 et Llama 3. Ces analyses révèlent les forces uniques de chaque modèle et leur potentiel futur.
Claude
Claude, en particulier Claude 3 Sonnet, se distingue également dans le paysage des modèles de langage. Des études montrent que Llama 3 a surpassé Claude 3 Sonnet dans plusieurs benchmarks. Meta a créé un benchmark avec 1 800 prompts où Llama 3 a montré des performances supérieures. Cependant, Claude reste un concurrent sérieux, surtout dans des cas d'utilisation spécifiques. Il est important de considérer ces résultats lorsque vous choisissez un modèle adapté à vos besoins.
Autres modèles
D'autres modèles comme Gemini Ultra et DeepSeek-R1 émergent également en 2025. Gemini Ultra atteint un score impressionnant de 90,0 % sur le MMLU, surpassant même des experts humains. Voici un tableau qui résume les performances de certains de ces modèles :
Modèle | Score MMLU | Score HumanEval | Remarques |
|---|---|---|---|
Gemini Ultra | 90,0% | 74,4% | Premier modèle à surpasser des experts humains |
GPT-4 | 86,4% | 67,0% | Référence traditionnelle en compréhension |
Claude 2 | ~78-79% | ~71% | Très bon niveau, comparable à PaLM 2 |
Ces modèles montrent que la compétition dans le domaine des LLMs est intense. Vous devez évaluer vos besoins spécifiques pour choisir le modèle qui vous convient le mieux. En 2025, avec la version "meta devoile llama 3 2", Llama 3 continue de se positionner comme un acteur majeur dans ce domaine.
Coûts et accessibilité
Modèles gratuits vs payants
En 2025, vous avez le choix entre des modèles gratuits et payants. Les modèles gratuits comme Llama et Gemini offrent des solutions accessibles sans frais. En revanche, des modèles comme GPT-4 et Claude v1 imposent des coûts. Voici un tableau qui résume les coûts par token pour différents modèles :
Modèle | Coût par tokens |
|---|---|
GPT-3.5 | 0,002 $/1000 tokens (750 mots) |
GPT-4 | 0,03 $/1000 tokens |
Gemini | Gratuit |
LlaMA | Gratuit |
Falcon | Gratuit |
Cohere | 0,4 $/1M de tokens |
PaLM | Aperçu public gratuit |
Claude v1 | 1,63 $/million de tokens (Prompt) et 5,51 $/million de tokens (Completion) |
Ces informations vous aident à évaluer les coûts associés à chaque modèle. Choisir un modèle gratuit peut être une excellente option si vous débutez.
Accessibilité pour les développeurs
L'accessibilité des modèles de langage influence fortement leur adoption par les développeurs. D'ici 2025, environ 70 % des nouvelles applications utiliseront des technologies low-code ou no-code. Ces technologies simplifient le développement et réduisent les coûts. Par exemple, développer une application classique coûte 100 fois plus cher qu'une application intégrant du low-code ou no-code. Pour une entreprise dépensant 300 000 € pour une application classique, le low-code permettrait de réduire ce coût à 5 000 € et le no-code à 1 000 €.
Impact sur les utilisateurs finaux
Les coûts et l'accessibilité des modèles de langage affectent également l'expérience des utilisateurs finaux. Voici un tableau qui montre les coûts annuels pour différents types d'applications :
Type d'application | Coût annuel (en €) | Réduction de coût (%) |
|---|---|---|
Application classique | 300 000 | 100% |
Application low-code | 5 000 | 98.33% |
Application no-code | 1 000 | 99.67% |
Ces chiffres démontrent que l'adoption de modèles accessibles permet aux entreprises de réduire considérablement leurs coûts. Cela se traduit par des applications plus abordables et accessibles pour les utilisateurs finaux. En choisissant des modèles adaptés, vous améliorez l'expérience utilisateur tout en optimisant les ressources.
meta devoile llama 3 2
Performances dans les benchmarks
Llama 3 2 a été soumis à des tests rigoureux pour évaluer ses performances. Voici quelques résultats clés :
Llama 3-70B-Instruct a été testé avec 1 800 prompts couvrant douze cas d'usage clés.
Ce modèle bat Claude 3 Sonnet, GPT-3.5, et Mistral Medium dans ces tests.
Les benchmarks montrent que Llama 3-70B se rapproche des performances de Llama 2-70B.
Ces résultats soulignent l'efficacité de Llama 3 2 dans divers scénarios d'utilisation. De plus, Llama 3 a été entraîné sur plus de 15 trillions de tokens, soit sept fois plus que son prédécesseur, Llama 2. La fenêtre de contexte a également été augmentée de 4096 à 8192 tokens, ce qui améliore la compréhension des textes longs.
Comparaison avec Gemma et Mistral
En comparant Llama 3 2 avec d'autres modèles comme Gemma et Mistral, vous constaterez des différences notables. Par exemple, Llama 3-8B surpasse Gemma 7B et Mistral 7B dans les benchmarks MMLU, GPQA, HumanEval, GSM-8K, et MATH. Ces performances montrent que Llama 3 2 se positionne comme un leader dans le domaine des modèles de langage.
Avantages des versions 8B et 70B
Les versions 8B et 70B de Llama 3 2 offrent des avantages distincts. Voici un tableau qui résume leurs performances :
Modèle | Performance (TFLOPS) | Benchmark Comparé |
|---|---|---|
Llama 3-8B | > 400 | Surpasse Gemma 7B, Mitral 7B, proche de Llama 2-70B |
Llama 3-70B | Moins probant | Surpasse légèrement Gemini 1.5 Pro, Claude 3 Sonnet |
Llama 3-70B-Instruct | N/A | Bat Claude 3 Sonnet, GPT-3.5, Mistral Medium, Llama 3 |
Llama 3-70B-Instruct (Benchmark) | N/A | 7ème position dans Lmsys Chatbot Arena |
Ces données montrent que chaque version a ses propres forces. Vous pouvez choisir celle qui correspond le mieux à vos besoins en fonction des cas d'utilisation.
En 2025, Llama 3 se démarque par ses performances impressionnantes face à ses concurrents. Vous constatez que les modèles de langage continuent d'évoluer, avec des systèmes plus puissants et accessibles. Voici quelques points clés à retenir :
La performance des LLM s'améliore constamment, avec des gains significatifs dans les simulations.
La démocratisation des LLM permet aux petites entreprises d'accéder à ces technologies.
De nouveaux modèles commerciaux émergeront, basés sur l'accès à des données privilégiées.
Choisir le bon modèle selon vos besoins spécifiques est essentiel. Cela vous permet d'optimiser vos projets et d'exploiter pleinement le potentiel des modèles de langage.
FAQ
Qu'est-ce que Llama 3 ?
Llama 3 est un modèle de langage développé par Meta. Il se distingue par sa capacité à générer du texte de haute qualité et à comprendre des contextes complexes. Il existe en plusieurs tailles, notamment 8B, 70B et 400B.
Comment Llama 3 se compare-t-il à GPT-4 ?
Llama 3 rivalise avec GPT-4 dans plusieurs benchmarks. Bien qu'ils aient des forces différentes, Llama 3 excelle souvent dans la génération de texte et le raisonnement. Les utilisateurs doivent choisir en fonction de leurs besoins spécifiques.
Quels sont les coûts associés à Llama 3 ?
Llama 3 est disponible gratuitement, ce qui le rend accessible à de nombreux utilisateurs. En revanche, des modèles comme GPT-4 et Claude peuvent entraîner des coûts. Cela influence votre choix selon votre budget.
Quelles sont les applications pratiques de Llama 3 ?
Llama 3 trouve des applications dans la génération de contenu, la compréhension du langage naturel et l'automatisation des tâches. Ces capacités améliorent l'efficacité dans divers domaines, comme le marketing et le service client.
Pourquoi choisir Llama 3 plutôt qu'un autre modèle ?
Choisir Llama 3 vous permet de bénéficier d'une performance élevée et d'une accessibilité. Sa capacité à traiter des contextes longs et à générer des réponses précises en fait un choix idéal pour de nombreux projets.
Voir également
10 Stratégies Pour Stimuler La Croissance Des SaaS En 2024
10 Obstacles Pour Les Petites Entreprises En 2024 Et Solutions
Top 10 Des Outils Essentiels Pour L'Étude De Marché En 2024
12 Visualisations Impactantes Qui Ont Défini 2024
14 Indicateurs Clés Pour Évaluer Le Marketing De Contenu En 2024

OFFRE JANVIER 2024
Gestion de tout votre digital PME :
490.- au lieu de 1'200.-
Mettez votre communication et visibilité en auto-pilote avec nous et concentrez-vous sur l'opérationnel de votre entreprise. Nous gérons pour vous les réseaux sociaux, les Neswletters, les publicités digitales, le SEO et la maintenance de votre site.
Et tout cela sans engagement, vous arrêtez quand vous voulez! Testez nos services!


© Copyright 2024 Digital Marketing PME.ch - Tous droits réservés.